2022. 12. 4. 23:19ㆍ오픈소스 기말/numpy
"Life is too short, You need python"
Python
Guido van Rossum이 만듬
executed언어, 큰 뱀에서 따옴
파이썬의 용도
- programming utility
- glue language(with c,c++)
- gui
- web programming , mobile programming
basic of python
type() : 변수의 type을 return해줌
파이썬은 할당된 값에 의해 자동으로 type을 지정해준다.
파이썬의 변수자체가 포인터이다.
id(): 주소값을 리턴해줌 ex) arr=[1,2,3] 어레이의 시작주소를 리턴
변수이름 _,a,A로만 시작
-camel case : myVariableName: ~
-phascal case:MyVariableName:~
-snake case: my_variable_name:~
tuple=(a,b) -> tuple 안에 내용은 절대 수정불가능
list=[a,b] -> 같은 타입으로 묶을필요없음 수정가능
dic={'a':'b'} -> key와 value로 이루어짐 key값은 수정불가능 -> list가 올수없음.
s1= set([a,b]) 연속적인 값을 인자로 받고 중복허용하지않음 ex) set([1,1,2,3])->1,2,3
if condition : while condition: for a in [1,2,3]: def add(a,b):
boty boty body body
Numpy
특징
- ndarray,broad casting
- 수학 함수, 선형대수학 ,random함수등등
- 큰 데이터 배열 디자인에 효율적이다.
import numpy as np
data=np.random.randn(2,3)
data
[[1.xxxx,0.xxxxx,1.xxxxxx]
[1.xxxx,1,xxxxxx,0.xxxxx]]
data*10, data+data 가능
data.shape
(2,3)
data.type
dtype('float64')
arr1=np.array(data) //ndarray만들기
arr1.ndim //몇차원인지
np.zeros(10) //0 10개짜리 배열
np.empty(2,3,2) //층,행,열 0으로 된 배열생성
np.arrange(15) // 0~14까지 배열생성
//type casting가능
arr1.np.array([1,2,3],dtype=np.float64)
arr1.np.array([1,2,3],dtype=np.int32)
arr=np.array([1,2,3])
float_arr=arr.astype(np.float64)
string_arr=arr.astype(np.string_)
arr=arr.astype(float_arr.dtype)
//arr+arr ,arr-arr 등등가능 같은사이즈에서
arr2>arr
true\false출력Broadcasting
두 모양이 다른 배열사이의 연산
두 array가 축길이가 같거나 하나의 길이가 1이여야한다.

4는 (1,0)배열로 생각해볼수있다. 4의 값으 1차원 배열의 요소에 broad casting되었다.
arr1.mean(0)은 column들의 평균을 구하는것이다. arr1.mean(1)은 row들의 평균
demeaned부분에서 (4,3)array와 (3,)array가 broadcasting됨.
더보기
3,4,2배열과 4,2배열을 만들어 broadcasting한다
결과는 이렇게 모든 층에 적용이된다.
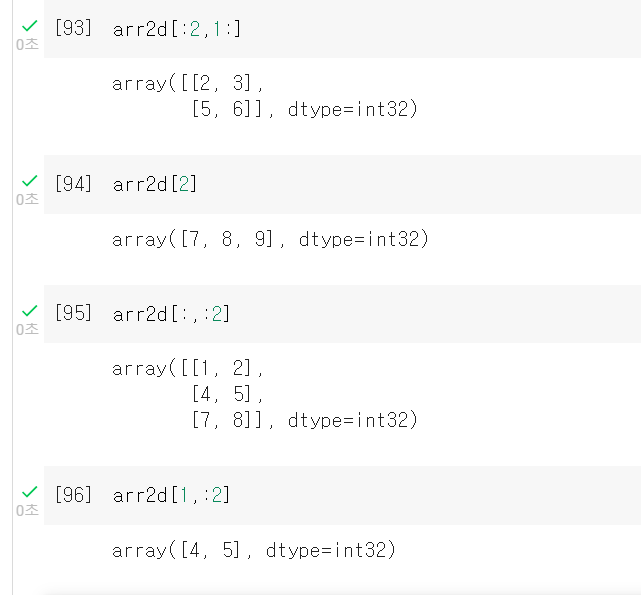
더보기INDEXING AND SLICING
arr_slice에서 값을 수정해도 arr에 적용이 되었다.
인덱싱은 기존의 vector처럼 하면된다
[:2] 는 [0,2) 0이상 2미만
[:]는 전체
[1:] 는 [1,end] 1이상 부터 끝까지퀴즈
A:
A:
A:
A:
정답
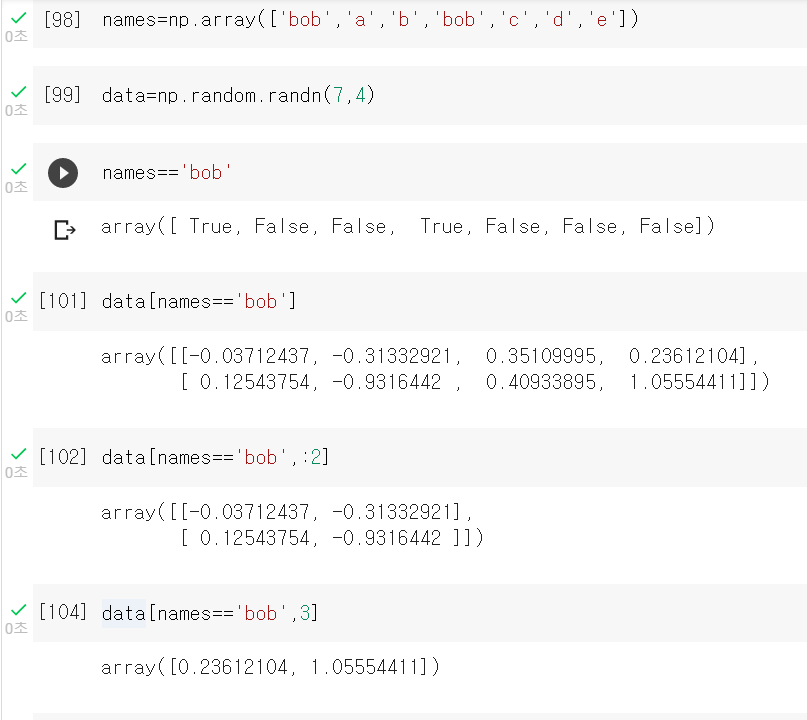
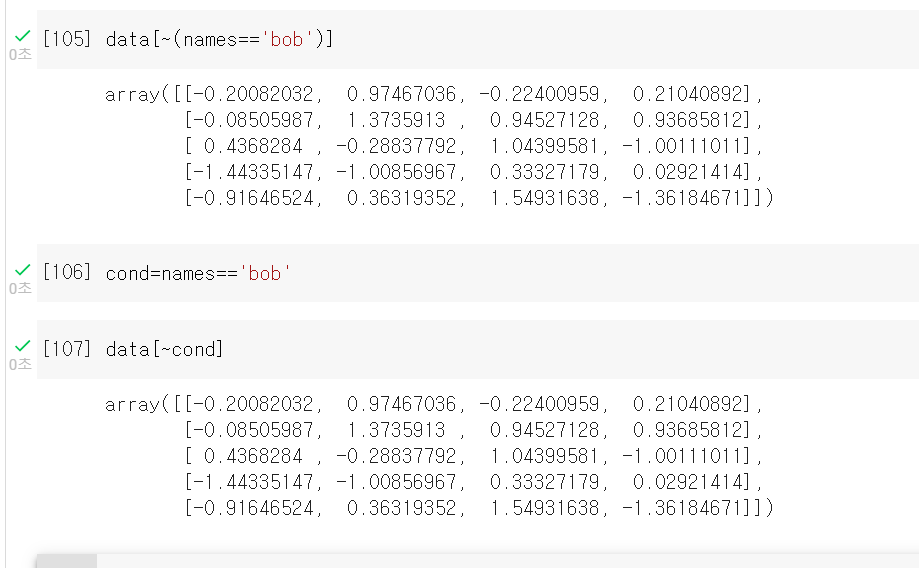
Boolean Indexing
names array에 조건을 대입해 boolean 배열을 만들어 indexing하는 방법 names=='bob'은 0,3이 true이다.
이런식으로 condtion을 변수에 넣어 쓰는방법도 존재한다.
-or연산자,대소비교연산자, boolean indexing을 통한 값 변환 모두 가능
Fancy indexing
NumPy에서 int 배열을 사용하여 인덱싱을 설명하기 위해 채택한 용어.
두 방식의 차이는 위에는 arr[1,0],arr[5,3],arr[7,1],arr[2,2]
아래는 arr[1,[0,3,1,2],... arr[2,[0,3,1,2,]중에서 :를통해 범위를 지정해주었다. :2로 바꾸면 20,23,21,22까지만 출력된다.
Transposing and swapping Axes
meaning :: 어떠한것도 복사하지않고 근본적인 데이터를 reshape하는 방법
format
arr.T (T attribute)
arr.transpose(~) ex) 3차원 0은 z,1은y2는 x
arr.swapaxes(0,1) -> swap column and row
*주의사항: 무조건 인자는 두개만
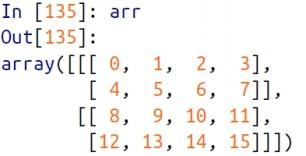
in arr=np.arange(15).reshape((3,5))
in arr
arr의 행과 열이 swap됨
np.dot()은 행렬의 곱함수이다.
transpose(원래의 y,z,x)
4의index는 (0,1,0)에서
(1,0,0)으로 바뀜.
행과 열을 바꿈
1의 index (0,0,1)->(0,1,0)
Universal function
범용함수: numpy에서 제공하는 수학함수들
exp(X) X를 밑으로하는 지수함수의 값
sqrt(): root값
반올림 올림,반내림,내림 등등output
r1=np.ceil(np.random.rand(2,5))
r2=np.floor(np.random.rand(2,5))
r3=np.round(np.random.rand(2,5),1)
r4=np.round(np.random.rand(2,5),2)
r5=np.round(np.random.rand(2,5))
r6=np.around(np.random.rand(2,5))
(print("\n",r1),
print("\n",r2),
print("\n",r3),
print("\n",r4),
print("\n",r5),
print("\n",r6))
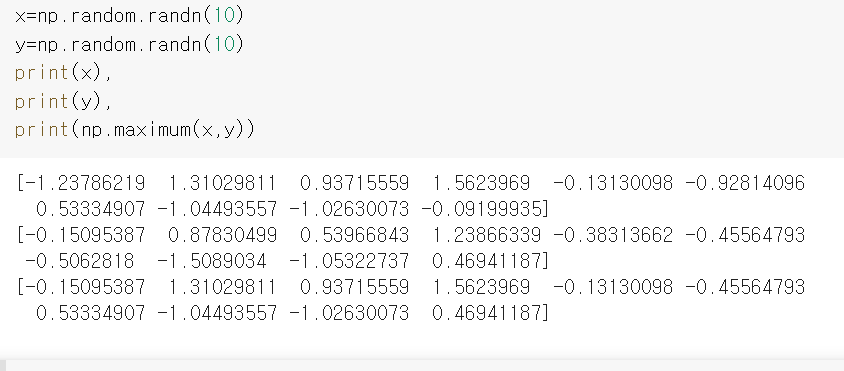
x,y의 [0:10]까지 중에 서로 큰값을 리턴
modf 함수 float의 1.12314 1과 0.12314로 나눔
multiple array returnout 옵션으로 arr에 sqrt()값을 넣어줌.
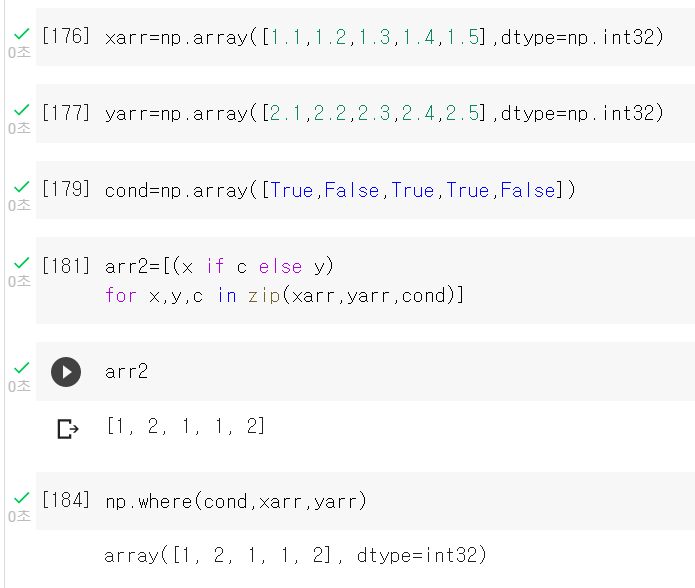
조건식사용
where함수는 다차원 배열에서 사용불가능,너무 큰 배열에서 사용불가능
where(cond,true일때,false일때)
통계,수학함수들
arr=np.random.randn(100)
(arr>0).sum()
output : 59 (random)1=True,0=False 즉, arr중에 양수의 개수를 세주는 역할을 한다.
.any () , .all()
any는 하나라도 true가있으면 true
all은 모두 true여야 true
numpy에서도 sort함수가 존재한다.
axis옵션을 입력가능함
또한 np.unique 함수는 중복을 제거해주는 역할을 하는데 정렬까지 해주어서
기존python에 sorted(set(arr))와 같은 기능을 한다.
in1d는 x 배열에 y배열의 요소가 포함되어있는지 true false로 리턴해준다.
-선형대수-
강의자료 보자
유사난수(pseudorandom number generation)
numpy.random.normal(loc=0.0,scales=1.0,size=None)
차례대로 평균의 위치는 어디에 놓을지 여기선 0에 놓는다고 기본값으로 되어있네요.
scale은 표준편차,size는 샘플의 사이즈를 의미하는 듯합니다.
np.random.seed(0)=np.random.RandomState(0)
같은 난수값을 출력하게해준다.
rng=np.random.RandomState(0)
np.random.seed(0)
np.random.randn(10)=rng.randn(10)
Random Walks
1000번 1,-1하면서 walk리스트에 cumsum
다중 walk
walk에 10도달한 최소시간
다중walk중 30에 hit한 walk의수
30의도달한 평균 시간